



記者顏大惟/綜合報導

其實只要是網站,多多少少都曾受到惡意程式(Bot)的攻擊,尤其是有會員系統的網站,這些 Bot 就會大量進行註冊並對網站造成負擔。因此網站必須要有一種認定「現在這在進行操作的用戶究竟是人類還是Bot」的機制。
大久保隆夫指出,這種機制的總稱就叫做「CAPTCHA」,而Google提供的機制則叫做「reCAPTCHA」,常看到的「我不是機器人」就是Google的「reCAPTCHA」服務。
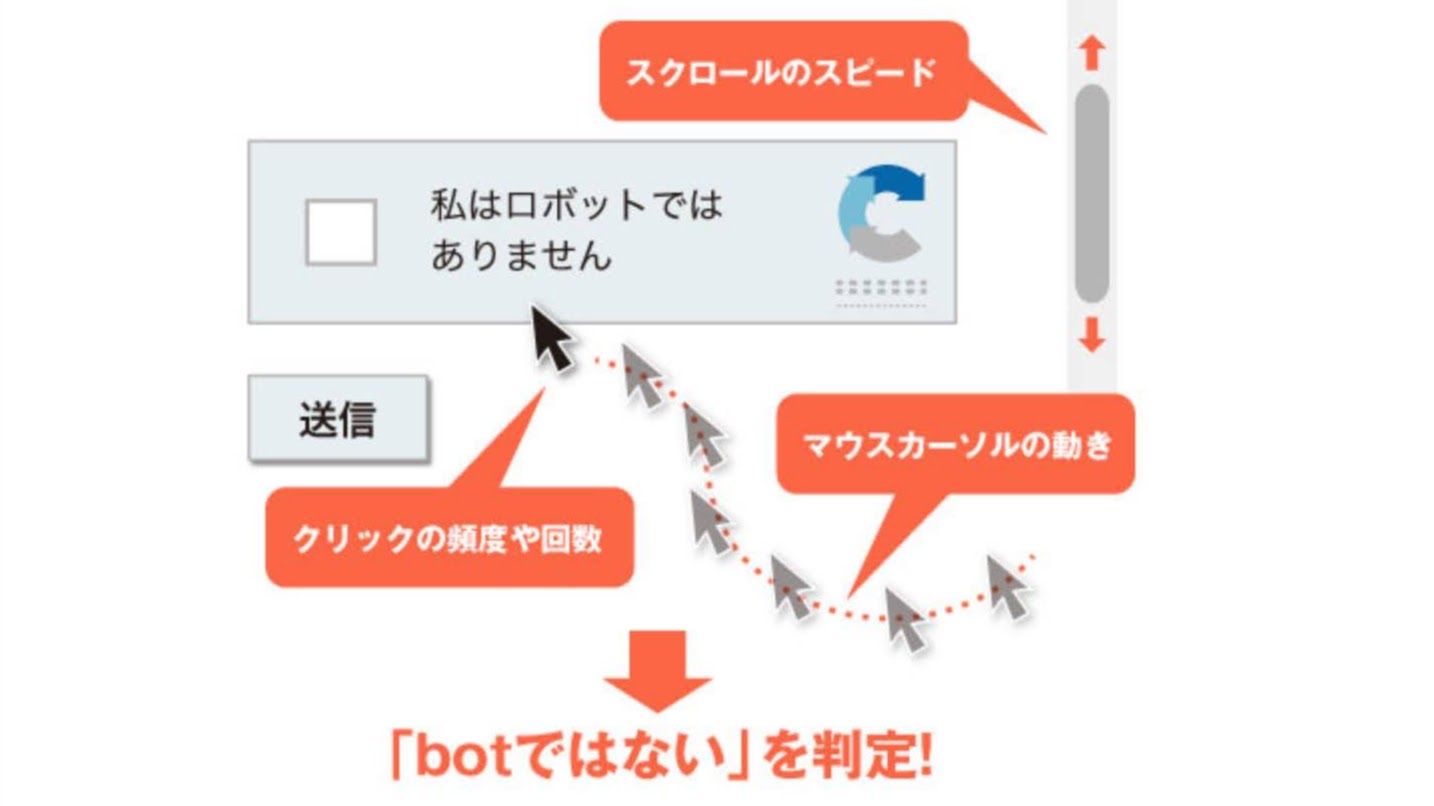
雖然現在的「reCAPTCHA」最常出現的是「我不是機器人」,但相信它的前身大家也一定都看過,那就是會出現各種歪七扭八的英文字圖片,並要求用戶輸入。之後AI慢慢變聰明,進化到現在的「我不是機器人」。那麼重點來了,「我不是機器人」如何知道你真的不是機器人呢?
當然有些部分無法準確判斷,這時候就會跳出「選取圖片」的機制,例如選消防栓、電線桿等等,再進一步的判斷。
至於為什麼一開始的扭曲文字 Google 不再使用呢?這是因為 Bot 也先進到可以正確的識別扭曲文字(9成9),反倒是人類只有約不到5成的正確率,因此有必要研發出全新的識別方式,成果就是現在看到的「我不是機器人」。
等到哪一天 Bot 再次進化,現在我們熟悉的「我不是機器人」也會慢慢地消失在歷史的洪流之中吧。
我是廣告 請繼續往下閱讀
其實只要是網站,多多少少都曾受到惡意程式(Bot)的攻擊,尤其是有會員系統的網站,這些 Bot 就會大量進行註冊並對網站造成負擔。因此網站必須要有一種認定「現在這在進行操作的用戶究竟是人類還是Bot」的機制。
大久保隆夫指出,這種機制的總稱就叫做「CAPTCHA」,而Google提供的機制則叫做「reCAPTCHA」,常看到的「我不是機器人」就是Google的「reCAPTCHA」服務。
雖然現在的「reCAPTCHA」最常出現的是「我不是機器人」,但相信它的前身大家也一定都看過,那就是會出現各種歪七扭八的英文字圖片,並要求用戶輸入。之後AI慢慢變聰明,進化到現在的「我不是機器人」。那麼重點來了,「我不是機器人」如何知道你真的不是機器人呢?
當然有些部分無法準確判斷,這時候就會跳出「選取圖片」的機制,例如選消防栓、電線桿等等,再進一步的判斷。
至於為什麼一開始的扭曲文字 Google 不再使用呢?這是因為 Bot 也先進到可以正確的識別扭曲文字(9成9),反倒是人類只有約不到5成的正確率,因此有必要研發出全新的識別方式,成果就是現在看到的「我不是機器人」。
等到哪一天 Bot 再次進化,現在我們熟悉的「我不是機器人」也會慢慢地消失在歷史的洪流之中吧。